Unsupervised Machine Learning Algorithms Implementation From Scratch
Following are the implementations of Unsupervised machine learning algorithms from scratch without using any Machine learning libraries
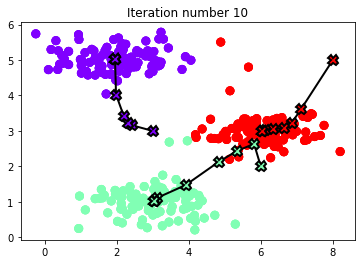
K-Means clustering GitHub Link
Implementation of K-means clustering from scratch using python. The implementation includes the two steps process
- assigning all samples to one of the closest centroids
- move centroids to the middle of those assigned samples.
However, the implementation is a little tricky for that I’ve implemented the following methods
- findClosestCentroids
- computeCentroids
- runkMeans
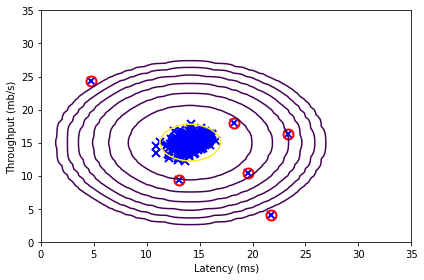
Anomaly Detection GitHub Link
Implementation of Anomaly Detection from scratch using python.
Step 1: To perform anomaly detection, first, need to fit a model to the data’s distribution
Given a training set {x(1), …, x(m)} (where x(i) ∈ Rn), you want to estimate the Gaussian distribution for each of the features xi .
For each feature i = 1 . . . n, you need to find parameters µi and σ2i that fit the data in the i-th dimension x(1)i,…,x(m)i (the i-th dimension of each example).
The Gaussian distribution is given by
p(x;μ,σ2)=12∗π∗σ√exp(−(x−μ)22σ2)
where µ is the mean and σ2 controls the variance.
Step 2: Estimating parameters for a GaussianYou can estimate the parameters, (µi, σ2i), of the i-th feature by using the following equations.
To estimate the mean, you will use: μi=1m∑mj=1x(j)i σ2=1m∑mj=1(x(i)−μ)2
Step 3: Selecting the threshold, ε
Now that you have estimated the Gaussian parameters, you can investigate which examples have a very high probability given this distribution and which examples have a very low probability.
The low probability examples are more likely to be the anomalies in our dataset. One way to determine which examples are anomalies is to select a threshold based on a cross-validation set. and here I have done it by running my algorithm for different values of ε to select the threshold ε using the F1 score on a cross-validation set.

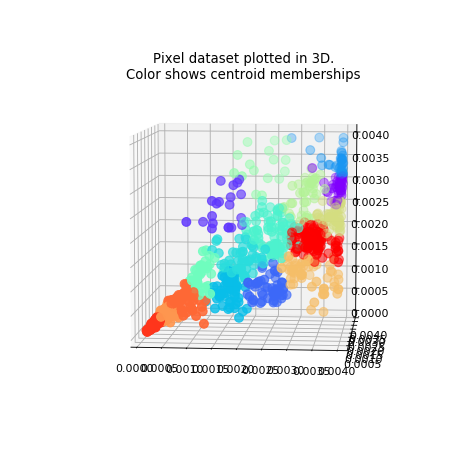
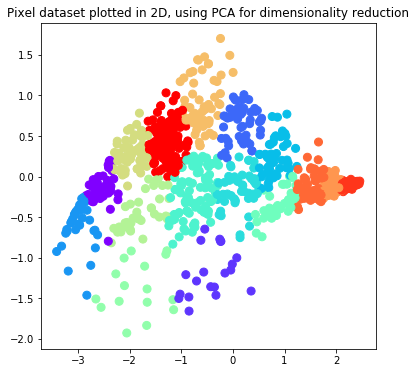
Principal Component Analysis(PCA) GitHub Link
The motivation of principal component analysis is mainly about data compression – for example, how to casting a high dimension data down to a lower dimension space. This will help saving space of data storage, also improving certain algorithm speed, and also to help visualization since a data more than 3D, 4D will become impossible to be visualized directly.
Courses & Certificates
-
Introduction to Database Systems (2019) edX-uc berkeley university-Joe Hellerstein
-
Introduction to Computer Science and Programming Using Python(2017) edX-MIT-Eric Grimson
-
CS 61B: Data Structures(2018) OCW-uc berkeley university-Jonathan Shewchuk
-
Mathematics for Computer Science/Discrete mathematics OCW- MIT-Prof. Tom Leighton
-
Linear Algebra(2019) OCW-MIT-Prof. Gilbert Strang
-
Single Variable Calculus(2020) OCW-MIT-Prof. David Jerison
-
Introduction to Probability (2020)OCW-MIT-Prof. John Tsitsiklis
-
Introduction to Compiler Construction(2019)OCW-The Paul G. Allen Center for Computer Science & Engineering-Hal Perkins
-
Artificial Intelligence(2018) edX-uc berkeley university-Dan Klein
-
Machine Learning-Stanford(2020) Coursera - Stanford - Andrew Ng
-
CS229 - Machine Learning(2020)Stanford - Andrew Ng
-
Introduction to Algorithms(2018)OCW-MIT-Srini Devadas & Erik Demaine
Conclusion
The following link to my Programming showcase repository on Github includes implementation of every algorithm discussed here